Let’s talk about two critical components of Generative AI applications: the data sources you supply and the prompts you craft to drive specific functions. Here’s the deal – these elements are not just a one-party show. They represent a shared responsibility between the customer and the provider. Now, the provider might be a software company like Lyzr, offering private agent SDKs that brilliantly simplify everything between the source data and the output. Alternatively, it could be a service provider specializing in custom app development using open-source platforms like Langchain.
Regardless of whether you’re teaming up with a software provider or a service provider, there’s one thing I want to underscore: the source data preparation and prompt engineering aspects in a Generative AI application development project are a collaborative effort. In this blog, I will delve into why I firmly believe in this shared responsibility, drawing from real-world examples to paint a clearer picture.
Preparing the Source Data for LLMs
Let’s delve into the first crucial element: source data. In the realm of Generative AI applications, most of the GenAI apps are powered by large language models (LLMs) like GPT-4, Claude, Mistral, and the like. Now, these LLMs excel at processing languages – think text, phrases, and the sort. However, they’re not quite the wizards in handling numbers, images, or multi-modal data. Sure, we’ve got models like GPT Vision dabbling in image processing, but let’s face it, we’re still a hop, skip, and a jump away from the likes of Gemini’s claimed multi-modal prowess.
Focusing on LLMs, most of these are driven by Transformer architectures, which primarily work better with languages, a.k.a text. Here’s the catch: when preparing data for ingestion into something like a vector store, it’s essential to normalize it so that LLMs can effectively make heads or tails of it. Picture this typical workflow:
Normalization: Take a bunch of PDF files. These are first normalized and converted into plain text. If you need to share these documents before processing, you can create a PDF URL for free to maintain easy access for all project collaborators. “
Chunking: This plain text is then chunked. You could go the straightforward route of chunking it every 500 words or opt for more nuanced methods like segmenting at the end of paragraphs or sections.
Vectorization: Post-chunking, the dataset is vectorized and stored in a vector database (like Weaviate) with an assist from an embedding model (like BGE).
But here’s a hiccup: if your original PDFs are sprinkled with images or numbers, they might end up as overlooked elements in the text, with images not being converted at all. This means that the data stored in your vector database might not be quite what you expected. Here is an example.
The chart data in the source PDF (left-hand side) looks entirely different post-normalization (right-hand side).
 | Self-assessed expertise with generative AI runs high 2 Q: How would you assess your organization’s current level of overall expertise regarding generative AI? (Oct./Dec. 2023) N (Total) = 2,835 Figure 3 44% rate their organization’s generative AI expertise as high or very high, but is such expertise even possible given the pace of the technology’s advancement? Little expertise No expertise Very high expertise High expertise Some expertise 10% 1% 9% 35% 45% |
As you may see, the parser agent just pulled all possible characters but the essence of the chart is lost. Now, if your chatbot or search engine tries to pull insights from the above ‘normalized’ data, you might end up blaming the agent or the LLM but the problem all along was with the source data.
This is exactly why we emphasize that data fed to LLMs should be primed for text processing. It’s a joint task – both customers and service providers need to brainstorm how to normalize the data so that LLMs can extract meaningful intelligence from it. In the upcoming section, we’ll walk through how we tackled data normalization to optimize it for LLM processing for one of our customers. To ensure the privacy of the customer, I will use the above ‘publicly available’ Deloitte deck.
As we saw earlier, our intelligent PDF parser was great at deciphering text but struggled with the chart. To enhance how our Large Language Models (LLMs) understood this context, we needed to upgrade our PDF parser embedded within our chatbot, chat agent, and search agent SDKs.
Here’s the step-by-step approach we took:
Identification: The first step was pinpointing sections that weren’t being converted into a text equivalent effectively. This meant singling out rich text areas that needed special attention.
Using a Multi-Modal LLM: Next, we brought in a multi-modal model like GPT-Vision. We fed it a specific prompt to transform this tricky section into a more understandable format. And let me tell you, GPT-Vision did a stellar job. The prompt we used helped articulate the chart’s content with remarkable clarity. Prompt used,
“Now convert this image into a detailed description of 100 words. Understand this presentation and illustration and come up with an accurate and detailed description. Explain the chart as if you explain this to a business leader. Mere translation of numbers in the chart is not desirable. Be accurate and use most of the words you find in the image instead of writing your own.”
| Before Vision Based Parsing | After Vision Based Parsing |
| Self-assessed expertise with generative AI runs high 2 Q: How would you assess your organization’s current level of overall expertise regarding generative AI? (Oct./Dec. 2023) N (Total) = 2,835 Figure 3 44% rate their organization’s generative AI expertise as high or very high, but is such expertise even possible given the pace of the technology’s advancement? Little expertise No expertise Very high expertise High expertise Some expertise 10% 1% 9% 35% 45% | This presentation slide showcases data on self-assessed expertise levels in generative AI within organizations. The headline emphasizes that 44% of respondents rate their generative AI expertise as high or very high. However, it poses a question about the possibility of such expertise in light of the rapid advancement of technology. The chart, labeled as “Figure 3”, is a donut chart displaying the distribution of self-assessed expertise levels. It indicates that 1% of the respondents claim no expertise, 10% acknowledge little expertise, 45% believe they have some expertise, 35% consider themselves to have high expertise, and 9% assert very high expertise in generative AI. The chart’s question asks, “How would you assess your organization’s current level of overall expertise regarding generative AI?” This data is from a survey conducted between October and December 2023, with a total of 2,835 responses. When explaining this chart to a business leader, one might emphasize the overall confidence in generative AI expertise among organizations while also highlighting the critical reflection on whether such self-assessment is realistic given the pace of technological development in the field. |
This enhancement significantly improved the LLM’s search efficiency and accuracy. When the results are fetched, the agent does more than just present a reader-friendly explanation. It also links back to the original source, indicating that the provided information is a transformed version of the original chart. This way, users can refer back to the original data if needed rather than solely relying on the converted text format.
This experience underscores a vital point: the deeper a customer’s understanding of their data – its purpose, data type, data sensitivity, and other crucial aspects – the better they can communicate its nuances to software or service providers. This collaboration is key for intelligently managing the entire data ingestion process in Generative AI applications.
Taming the LLMs with Intelligent Prompt Engineering
Now, let’s peek into the lifecycle of a Generative AI application. Imagine this: data gets ingested, and the Lyzr agent SDK is the maestro handling all the nitty-gritty in the middle. Then comes another crucial element – the prompt. These prompts are the backbone of our chat agents and RAG search agents.
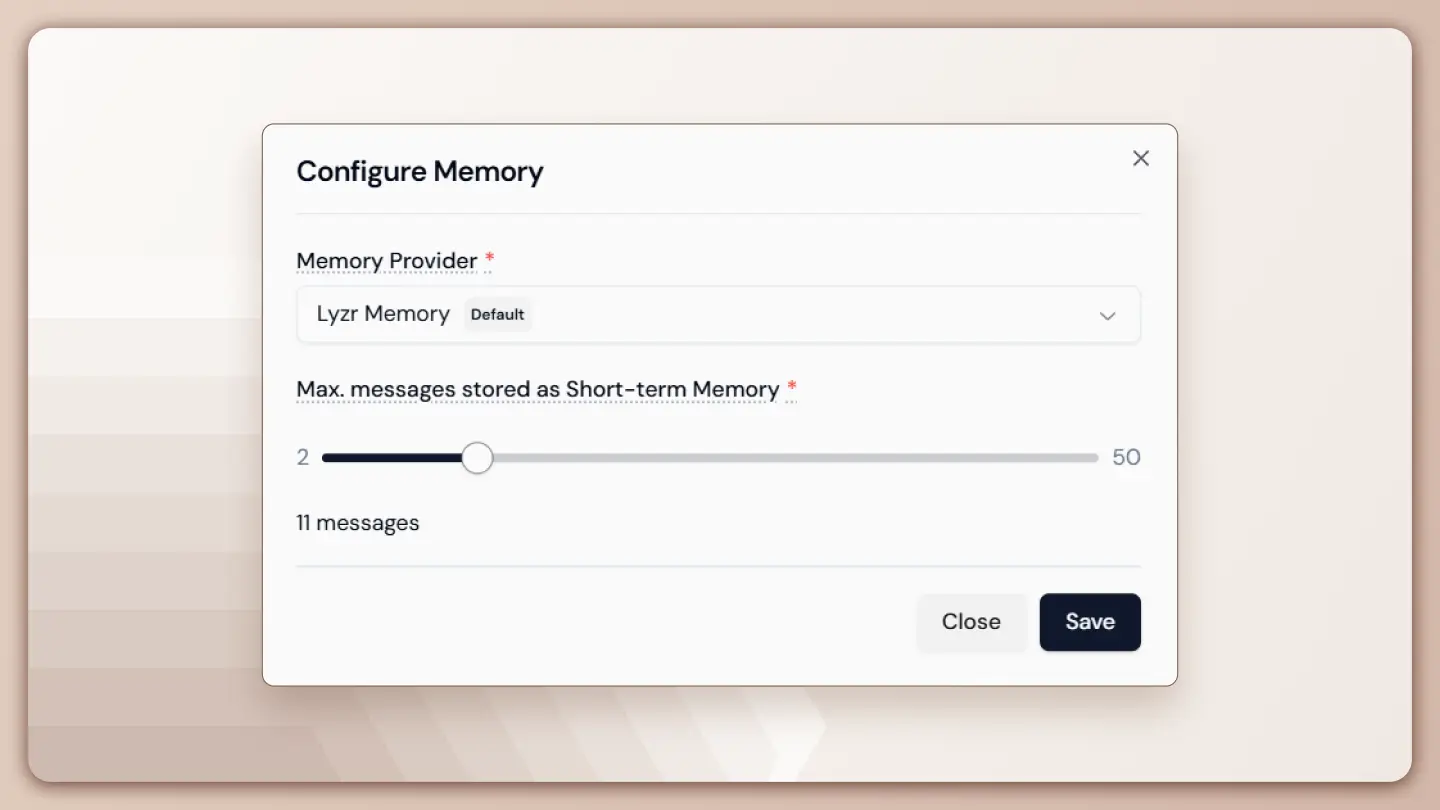
Here’s the scoop: all our agents are equipped with a base prompt ready to roll right out of the box. You can grab one of our open-source SDKs (https://docs.lyzr.ai/lyzr-sdk/opensource/), give it a whirl, and bam – it works. But hold your horses when we’re talking about production-grade, enterprise-level applications, where sticking to the base prompt may not cut it. We’re talking about adding personality, specific instructions, safe AI guardrails, and a defined task for the agent to accomplish. These finer details? They usually come straight from the customer’s desk. That’s why prompt engineering is a shared responsibility.
In my book, large language models are the rock stars of the tech world, and they’re here for the long haul. In the next decade or so, we’re going to see these models strut their stuff even more. Prompt engineering, my friends, is set to become as essential as, let’s say, writing emails. It’s a skill that anyone in the IT and tech space should have up their sleeve.
For starters, the OpenAI Playground is a fabulous place to dip your toes into the world of prompt engineering. But guess what? We’re all about making life easier for our customers. Enter Prompt Studio – our very own, easy-to-use prompt engineering platform. It’s like having a treasure trove of templates at your fingertips – Chain of Thought, React, FiveShot, you name it. These top-notch templates are your ticket to crafting enterprise-grade, production-ready prompts.

Link to Lyzr Prompt Studio – https://promptstudio.lyzr.ai/login
But it’s not just about picking a template and calling it a day. You can compare these prompts across different models and techniques, playing around to find the perfect match for your needs. It’s like a ‘try before you buy’ scenario but for prompts. And once you hit the jackpot with the right prompt, you’re all set for your production applications. Believe me, half the magic in Generative AI lies in designing those killer prompts.

Crafting prompts is a bit like tailoring a suit – it’s all about the specific needs and requirements. Take a chatbot, for instance. The structure of its prompts is going to differ vastly from those of a search agent. In the case of a search agent, the focus is heavily on retrieval accuracy and the volume of data it can efficiently handle. This contrasts with an RAG agent, which might be part of a larger application workflow. Here, the prompt needs a careful balance between speed, size, and accuracy.
So, what’s the bottom line? The way you engineer your prompts is going to shape the performance and outcome of your application significantly. It’s like the secret sauce that gives your app its unique flavor.
Now, for those looking to master the art of prompt crafting, there’s a wealth of knowledge out there. I’ve got a couple of go-to resources that I swear by. First up, there’s this ever-evolving repository – a prompt engineering guide brimming with best practices. It’s a goldmine!
Then there’s this recent academic paper, a real eye-opener about constructing high-quality prompts.
These two are my guiding stars in the vast universe of prompt engineering.
But wait, there’s more! To make things even smoother for our customers, we decided to up the ante with ‘Magic Prompts’. Picture this: you start with a simple one or two-line prompt. Magic Prompts then waves its wand and transforms it into something far more sophisticated, in line with the best practices highlighted in those invaluable resources I mentioned. It’s like having a prompt wizard at your fingertips, ensuring your prompts are not just good but great.

Link to Lyzr Magic Prompts – https://magicprompts.lyzr.ai/
Let’s dive into the nitty-gritty of how Magic Prompt spins its magic. We’ve cherry-picked some of the most impactful best practices in prompt crafting and baked them right into this tool. What this means for you is that your simple, straightforward prompts can be transformed into top-tier, best-practice ones in a snap. Let me give you a quick tour of how it works.
The input

And the Magic Prompt Output

Peering into the crystal ball, will these processes evolve and improve? Absolutely! As we encounter more edge cases, we continually refine our intelligent source data parsers. And it’s not just us; there’s a whole community out there making strides. Take Unstructured IO, for instance. They’ve mastered the art of crafting models that deftly parse input data into tables and non-table formats. Or look at JP Morgan’s recent leap with DocLLM – their fine-tuned model excels in deciphering contract documents.
DocLLM Paper – https://arxiv.org/abs/2401.00908
What this evolution signifies is a gradual reduction in the need for customers or service providers to make painstaking adjustments. The technology is becoming more intuitive and more user-friendly. On the prompt engineering front, we’re expecting similar advancements. We’re integrating MagicPrompt as a standard feature in all our agents, ensuring even the base prompts are of a higher caliber. Plus, it’s available as a complimentary tool for everyone, allowing you to refine your prompts with ease.
But here’s the exciting part: as we look forward to advancements like GPT-5 and Llama3 models in 2024, these models are expected to become even more adept at interpreting simpler prompts. The goal is for the base prompts of these LLMs to shoulder the heavy lifting, enabling users to focus on their core tasks without getting bogged down in complex prompt engineering. In other words, LLMs are on track to become smarter at handling simpler inputs.
These anticipated changes are what I see on the horizon. But until then, we’ve got your back. Dive into our free tools and elevate your prompt engineering skills to the pro level. Here’s to becoming a prompt engineering champ – best of luck!
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here